深層学習(ディープラーニング)では、人間の神経系を模した「ニューラルネットワーク」という仕組みが使われますが、入ってきた多くの情報に重み付けしたり取捨選択するのに、「活性化関数」というものが用いられます。
これを、特許情報の「先読み」に使えないかなあ、と思って、幾つか試しているところです。以下、題材があまりよろしく無いのですが、あくまで方法論としてどういったものが考えられるか、少しだけ触れてみたいと思います。
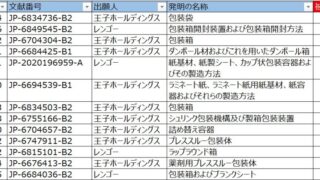
題材としては、前回の記事の最後の方で取り上げた、キーワードの件数トレンドを用います。
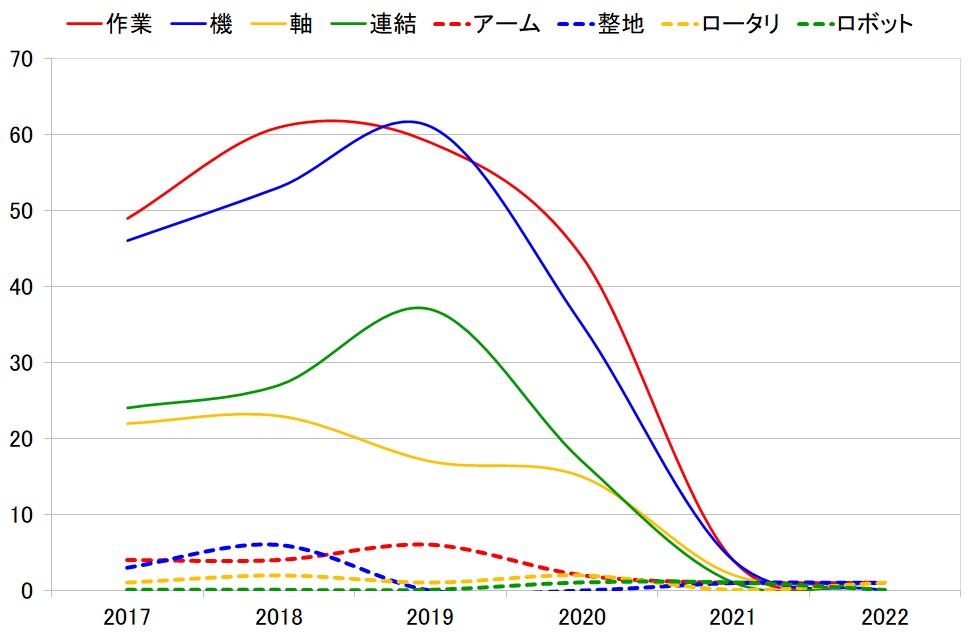
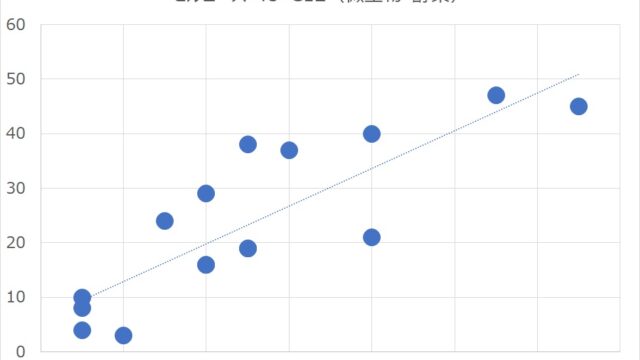
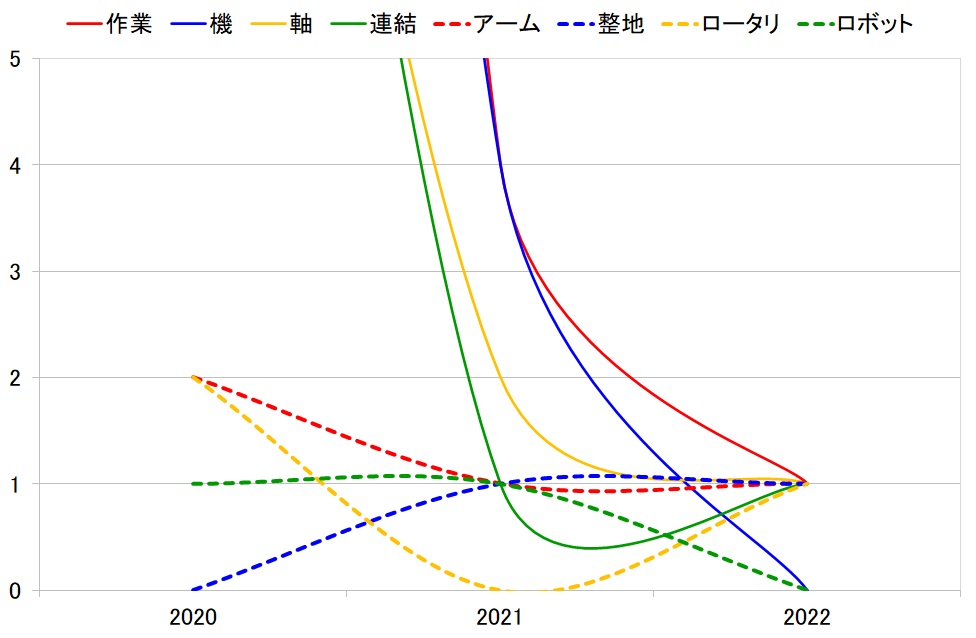
この最近3年間を拡大表示すると、下図の通りです。
これに、「活性化関数」を掛けることで、最近に出現して伸びてきそうなキーワードを炙り出します。・・・と言っても、「活性化関数」が何なのかを説明しないと不親切なので、簡単に説明しておきます。
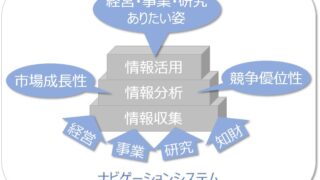
幾つかありますが、具体的にグラフで示すと、例えば以下の通りです。

それぞれ、一次関数(黒実線)、指数関数(緑実線、赤実線)、双曲線正接関数(水色破線、「タンエイチ」とも言う)、シグモイド関数(ピンク破線)、といったものです。
これらはいずれも「右肩上がり」になっており、この関数を掛け算することで、横軸の右に行くほど重みが大きくなります。関数の形によって、その重み付けの程度が変わることになります。一次関数よりも対数の方が、より横軸の右の値を重く扱うことになります。
この活性化関数を、特許件数のトレンドに掛け算する意味は、単純に「最近に出願された特許ほど価値があると見做す」ということです。例えば、2010年に出願された特許が1件、2020年に出願されたより新しい特許が1件あった場合、同じ1件ではなく、新しい方を100件、1000件、10000件の価値があると「見做す」という考え方です。
そうして活性化関数を掛け算された件数トレンドが下図です。ここでは、e^x(exponentialのx乗)を用いています。改めて、活性化関数を掛ける前(下図)と比べてみると、どのように変化するかが分かると思います。

上記データは、活性化関数を掛けただけでなく、さらに過去の出現頻度を加味していますが、複雑になるので説明は省略します。
この手法が、本当にこれから伸びそうなキーワードを炙り出せているのかは、現時点ではよく分かりません。幾つかの事例で良そうしてみて、かつ、数年後に実際どうだったかを検証してみるという、手間の掛かる作業が必要になります。
・・・飽きっぽい筆者には、なかなか難しい課題ではあります。
お読みいただきまして、誠にありがとうございました!
ブログランキングに参加中!