
知らない技術分野を調査するには?~特許分類からブレイクダウンする特許分析
えがちゃん
知財で先読み!「ゆめ知財」
特許マップやIPランドスケープでは、テキストマイニングは欠かせない手段です。
昔は、高価な専用ツールしかありませんでしたが、機械学習やディープラーニングなど、AIの普及により、無料で手が出せるようになってきました。
当サイトでも「SimPat-Tex」という特許用のテキストマイニング・サービスを提供中ですし、また、より幅広いサービスを展開するサイトとして、ユーザーローカル社の「AIテキストマイニング」があり、無料とは思えないほど機能が豊富、利用可能な文字数も多く、解析速度も速くて便利です。
今回は、AIテキストマイニングなどを利用した、無料のテキストマイニング事例を紹介します。

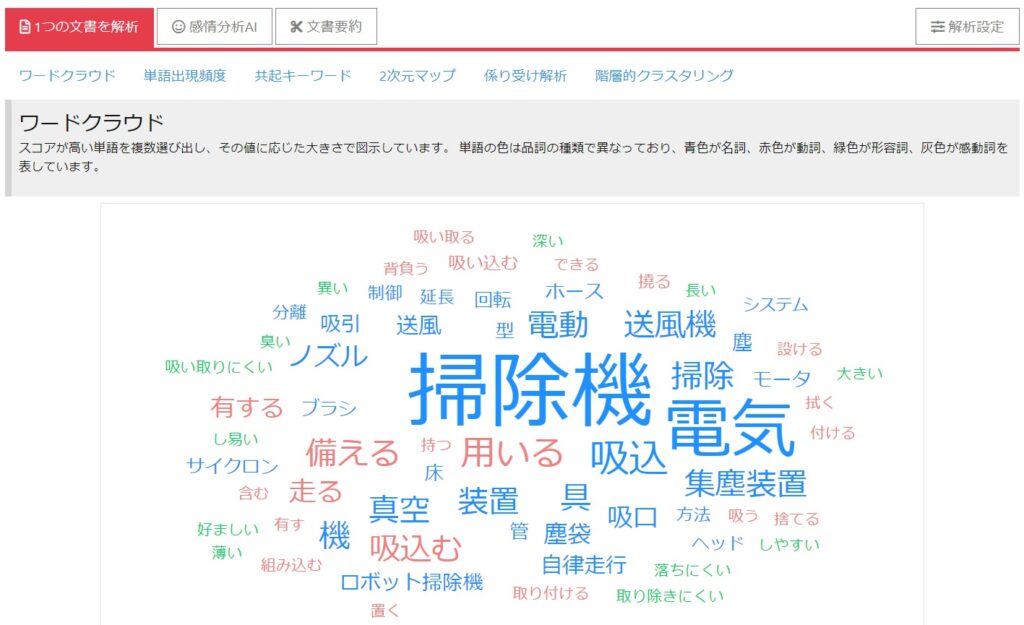
ユーザーローカルのインターフェースは簡単で、文章をコピペするだけで、結構な文字数でも一気に解析してくれます。数1000件の特許でも、特に問題はありません。

単語が”雲”のように集まって表示されるものです。出現頻度の多いワードを大きく、そうでないものを小さく、似たようなワード同士は近く、という感じで表示されます。
このような機能は、有償の特許検索ツールにも搭載され始めています。ユーザーローカルの場合、品詞で色分けもされます。
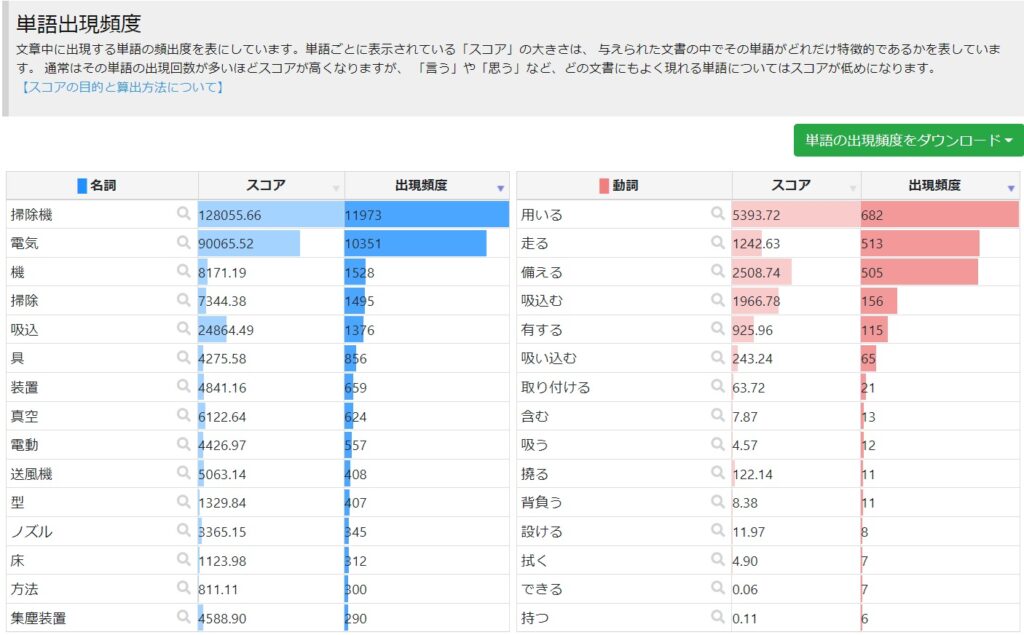
出現頻度の多い順に並んだワードのリストで、ユーザーローカルではExcel形式でダウンロードできます。品詞別も表示されます。
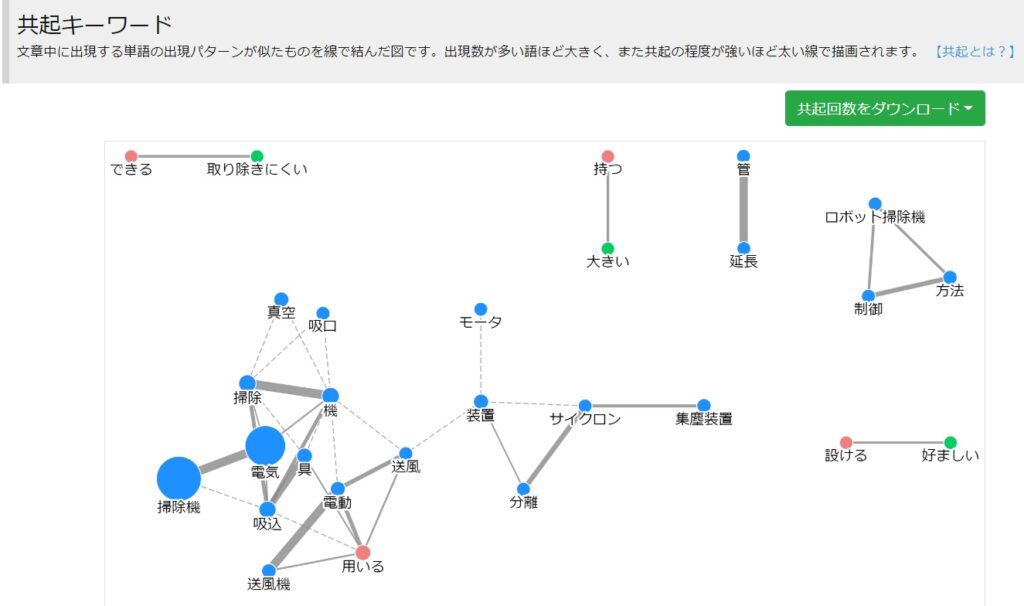
一緒に出現することが多いワード同士が線で結んで表示されます。そのワードの意味合いを判別するのに便利です。
出現する傾向が似たものが近く配置されます。筆者はあまり使いませんが、特許の塊が幾つあるかなど、判別する場合の傍証にはなるかと思われます。
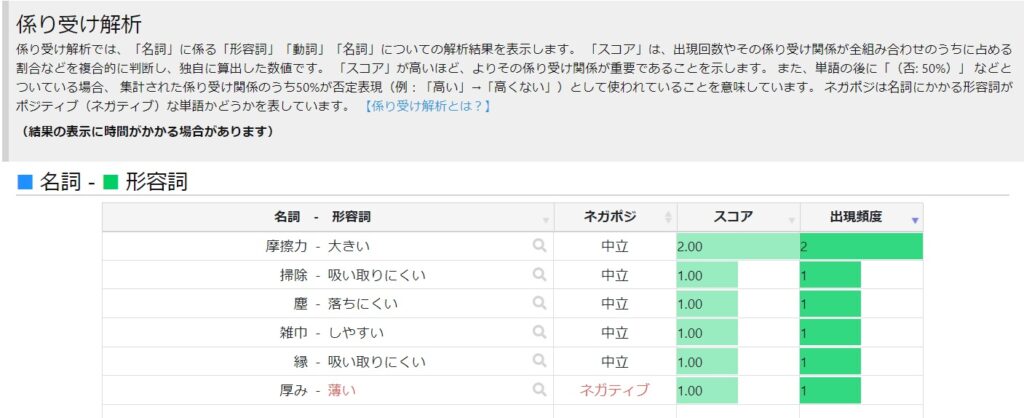
そのワードがどんな意味合いで使われているか、係り受けの関係により分かり易くなります。
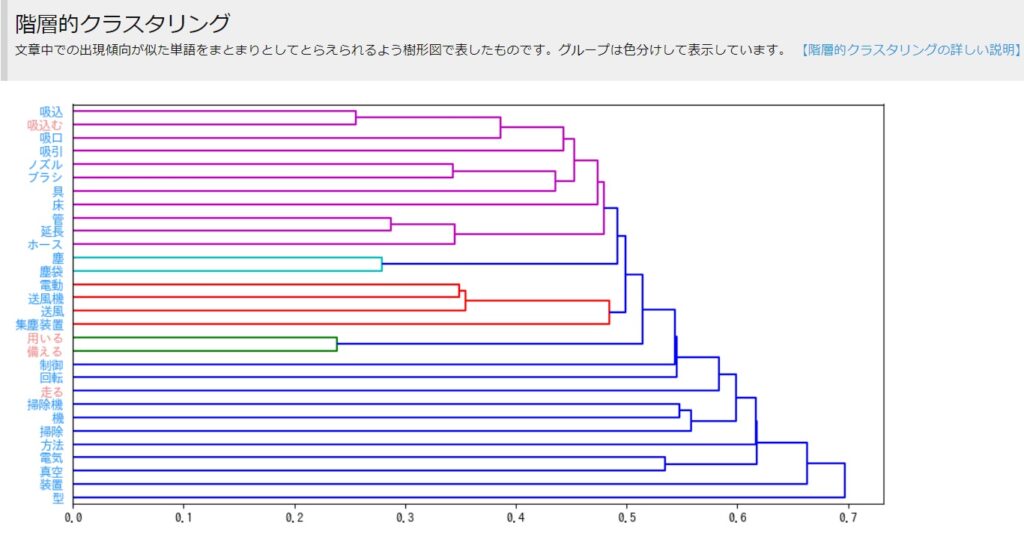
出願傾向が似たワードの関係性を樹形図で表示したものです。これも、特許の塊を捉える一助になります。
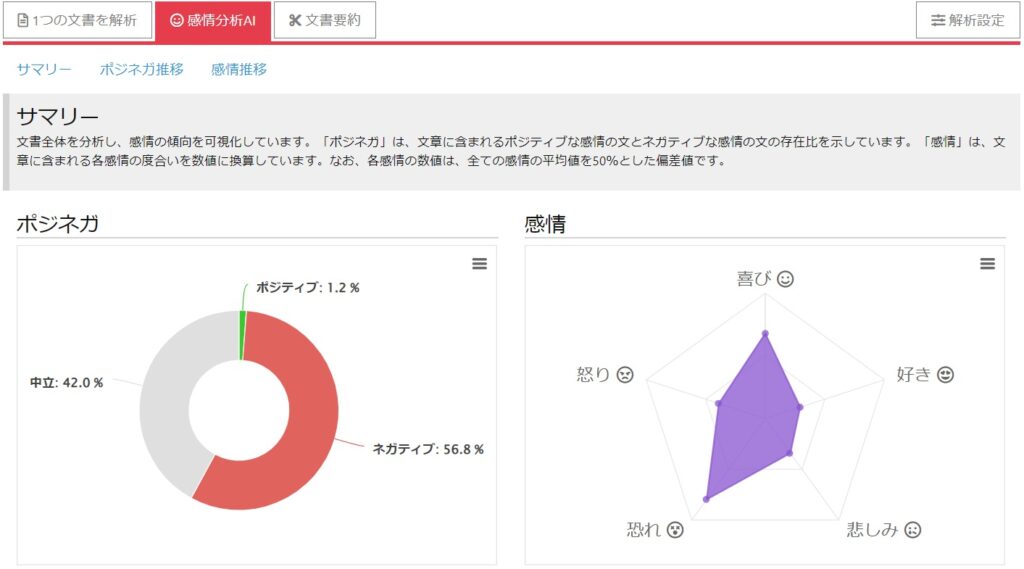
その文章が、喜怒哀楽など、どのような感情を表現しているか判別するという、おもしろい機能です。SNSのメッセージが非難か賞賛かなど、判別するのに使えるかと思われますが、特許分析ではあまり出番は無いかも知れませんね。
今回は、ユーザローカルの「AIテキストマイニング」を例に、テキストマイニングで何ができるかをご紹介しました。
当サイトでも、テキストマイニングによる特許分析をいろいろ紹介していきたいと思いますので、ときどきチェックしてみてくださいね。
Views: 1243



