無料で特許マップを生成!「Pat Map Generator」の利用方法
えがちゃん
知財で先読み!「ゆめ知財」
特許データをテキストマイニングするWebアプリ「SimPat Tex(無料版)」について、利用方法や注意点などを解説します。
テキストマイニングとは、文字のデータ(特許の場合は「発明の名称」や「要約」)を、単語に分割(名詞、動詞、形容詞等)して、有益な情報を抽出することです。
鉱山から貴金属やダイヤモンドを採掘することを「マイニング」(Mining)と言いますが、それにならって、「テキスト」データから有益な情報を「マイニング」するという意味で、「テキストマイニング」と呼びます。
ここでは、単語に分割するだけの行為も含めて「テキストマイニング」と呼びます。

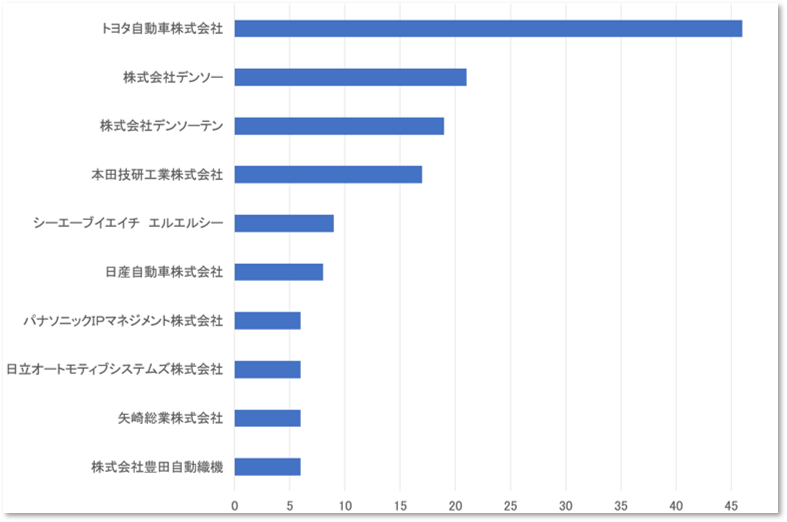
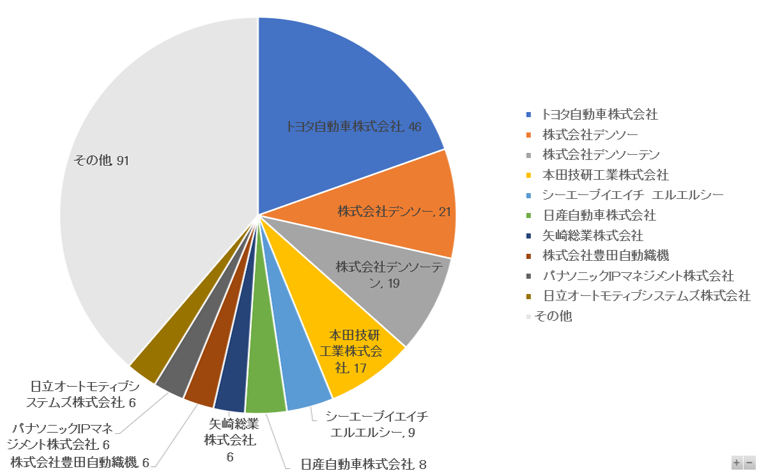
SimPat Tex(無料版)の操作画面と操作手順は以下の通りです。

①「特許データを登録」の欄に、特許データのファイルをドロップまたはクリックして登録します。
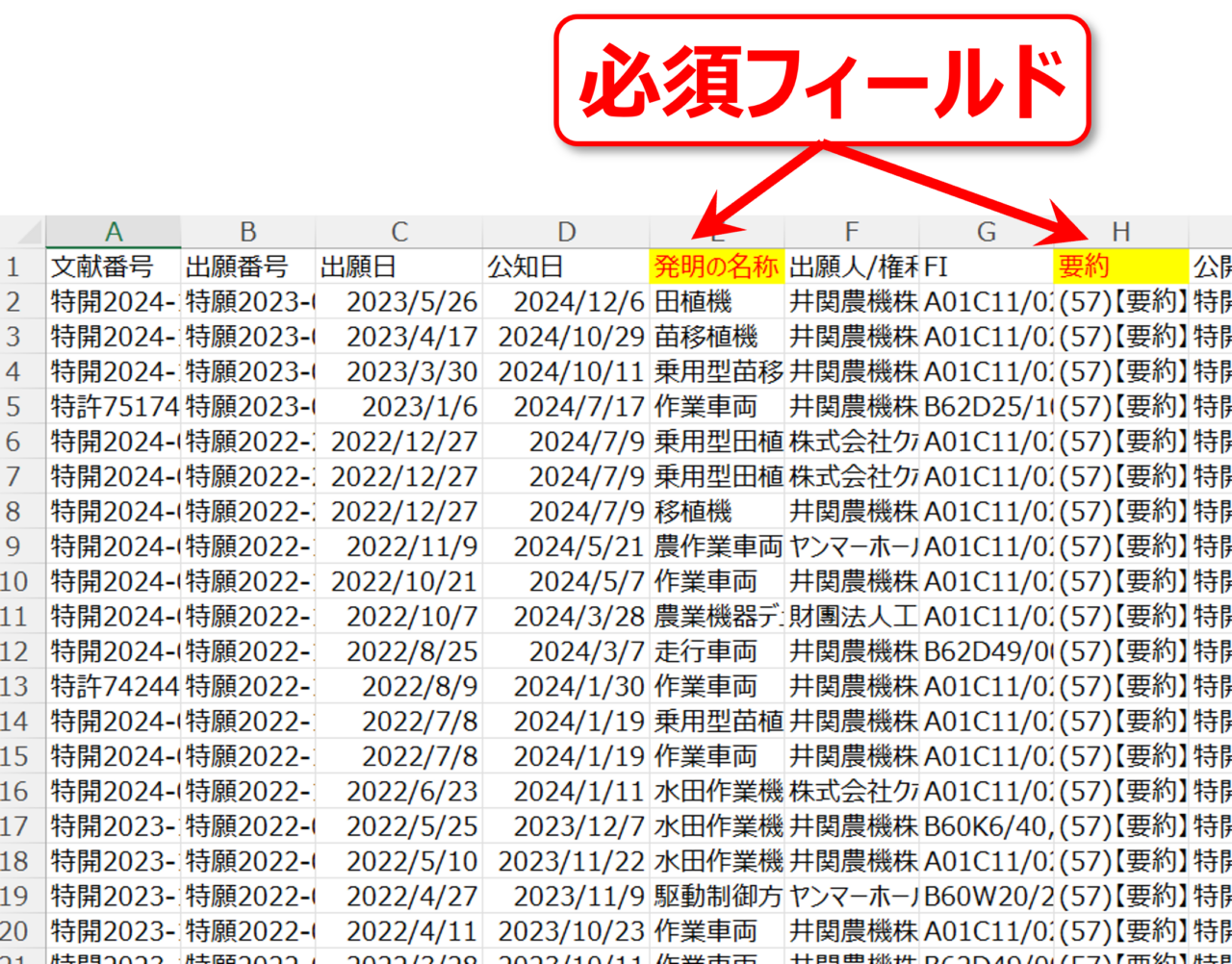
②「辞書を登録」の欄に、抽出語、除外語、同義語に関するファイルをドロップまたはクリックして登録します。これらの辞書に関しては後述します。
③「テキストマイニングを開始」ボタンをクリックして、データ解析を開始します。(結果については後述します。)

④「サンプルデータを表示」ボタンをクリックすると、テキストマイニング結果のサンプルが表示されます。
テキストマイニングの結果については、抽出語、同義語、除外語の各辞書を使って、調整をすることができます。
テキストマイニングの結果に関わらず、必ず表示したい単語は、テキストファイル(拡張子:txt)に保存して、「抽出語」の欄にアップロードしておけば、強制的に抽出して表示します。
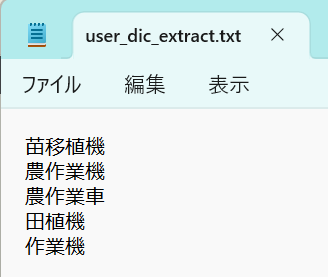
ただし、使用している形態素分析プログラムの都合上、抽出されない場合もあるので、その点はご留意ください。
上記とは逆に、除外したい単語がある場合、テキストファイル(拡張子:txt)に保存して、「除外語」の欄にアップロードしておけば、強制的に除外します。
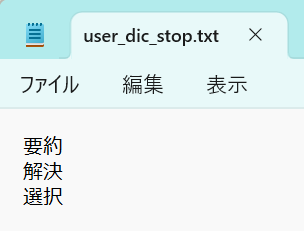
なお、以下の単語群はデフォルトで除外されます。また、1文字だけの単語も除外されます。
“こと”,”もの”,”よう”,”ため”,”それ”,”これ”,”どこ”,”あれ”,”あと”,”とも”,”うち”,”および”,”お呼び”,”及び”,”ならびに”,”並びに”,”または”,”又は”,”要約”,”課題”,”解決”,”手段”,”解決手段”,”特徴”,”前方”,”後方”,”上下”,”左右”,”前記”,”上記”,”後述”,”上方”,”下方”,”前部”,”後部”,”上部”,”下部”,”作業”,”装置”,”工程”,”行程”,”構成”,”配置”,”部分”,”全体”,”位置”,”制御”,”材料”,”容易”,”従来”,”前側”,”後側”,”側方”,”形成”,”状態”,”状況”,”戴置”,”中央”,”場合”,”選択”,”前後”,”提供”,”本体”,”右”,”左”,”上”,”下”,”間”,”方法”,”製法”,”製造方法”,”生産方法”,”所定”,”*”,”可能”,”可能性”,”図”,”選択図”,”部”,”回”,”側”,”機”,”前”,”後”,”複数”,”主”,”台”
同じような意味の単語は統合することができます。
CSVファイル(拡張子:csv、文字コード:utf-8)またはExcelファイル(拡張子:xls、xlsx)を準備し、下図のように、A列に統合前のワード、B列に統合後のワードを記載して保存して、「同義語」の欄にアップロードしておけば、統合後のワードに置換します。

データ解析が完了すると、操作画面の下に、「ワードクラウド」と「ダウンロード」のタブが表示されます。

「ワードクラウド」(Word Cloud)とは、テキストマイニングによって切り出された単語群について、出現頻度が多い単語ほど大きく表示、出現頻度が少ない単語を小さく表示し、適当に配置・配色してビジュアル表示したものです。
本アプリでは、文字データである「発明の名称」および「要約」を対象に、ワードクラウドを生成します。画像を右クリックして、別窓への表示やダウンロードも可能です。
①「発明の名称」のワードクラウド

②「要約」のワードクラウド

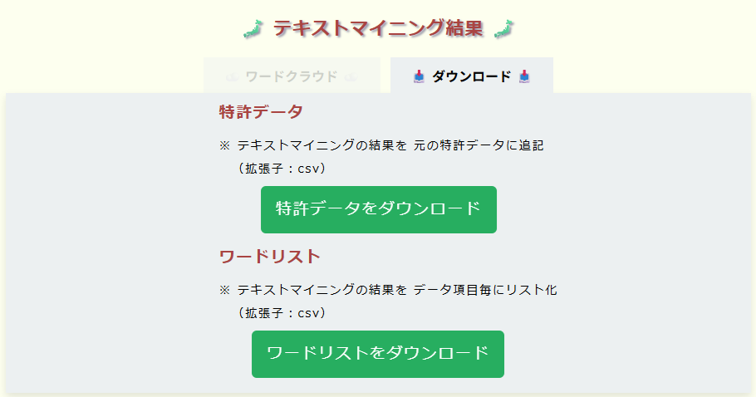
テキストマイニングの結果は、ダウンロードできます。ダウンロードするデータの形式は、以下の2種類です。
①特許データ
「発明の名称」および「要約」から切り出された単語群のリストは、それぞれ「発明の名称ワード」および「要約ワード」というフィールド名で、元の特許データに追記され、CSVファイルとしてダウンロードできます(「特許データをダウンロード」ボタンをクリック)。

②ワードリスト
「発明の名称」および「要約」から切り出された単語群を、出現頻度が多い順にソートして、「発明の名称」「要約」の順に並べたリストを、CSVファイルとしてダウンロードできます(「ワードリストをダウンロード」ボタンをクリック)。

よく発生するエラーは、「ファイルが無効です。」のエラーです。これは、ファイルを登録してから時間が経過したなどの理由で、システムの内部処理によりファイルが削除されてしまう、などが理由です。この場合、ブラウザの画面をリロードしてやり直してください。

次に発生しやすいのは、軸データ項目の選択ミスや、ファイルのデータサイズが大き過ぎる場合です。

その他、ダウンロードしたデータに手を加えた場合、以下のようなエラーが出ます。

ご利用にあたっては、以下の点をご了承ください。
できるだけ多くのみなさまに、広くご利用いただければ、と願っております。ご意見やご要望などは、「お問い合わせ」からお寄せください!
Views: 1