「DeSci Japan 2025」にモデレーターとして登壇します
えがちゃん
知財で先読み!「ゆめ知財」
ウェブ上で特許データをテキストマイニングする特許テキストマイニングシステム「Pat Text Mining」について、試験運用(無料)を開始しました。

J-PlatPatで検索してダウンロードした特許データのCSVファイルを、ブラウザからアップロードすれば、テキストマイニングの結果が自動的に生成、ブラウザに表示されます。テキストマイニングする対象は「発明の名称」および「要約」です。
以下、システムの使い方などを説明します。
初期画面は下図の通りです。(試行版のため、随時変わるので、ご承知おきください。)
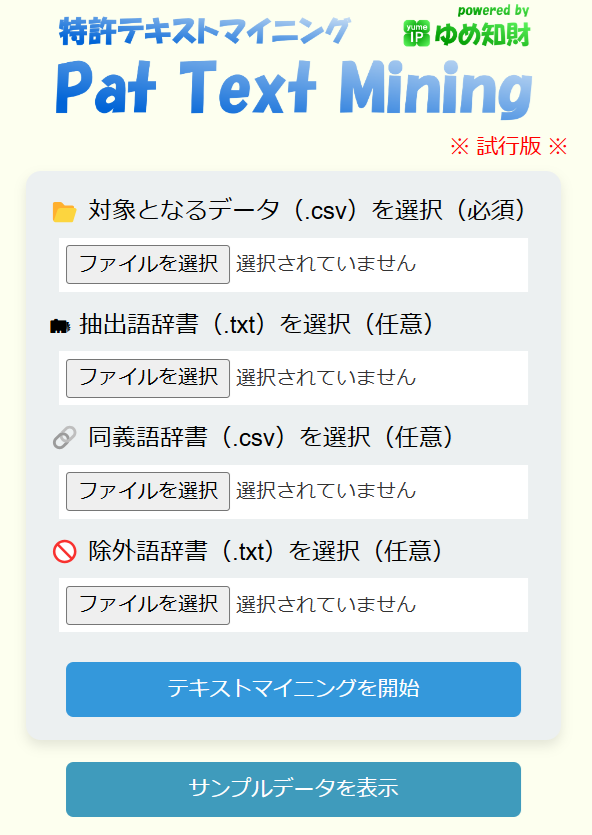
「対象となるデータ(.csv)を選択」から、J-PlatPatで検索してダウンロードした特許データのCSVファイル(UTF-8形式)を、「ファイルを選択」をクリックして選択して、「テキストマイニングを開始」をクリックすれば、テキストマイニングが始まります。
なお、テキストマイニングは自動的に行われるので、結果が気に入らない場合もあるかと思います。その場合、以下のような手段で修正が可能です。
テキストマイニングの結果は、操作画面の下に3種類、表示されます。
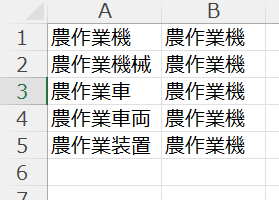
ひとつめは、アップロードしたCSVファイルに、テキストマイニングした結果を追記したCSVファイルです。「データをダウンロード」をクリックすれば、ダウンロードされます。

テキストマイニングされた結果は、CSVファイルの右端に「発明の名称ワード」および「要約ワード」という新たな列が設けられ、切り出された単語がコンマ区切りで列挙されます。
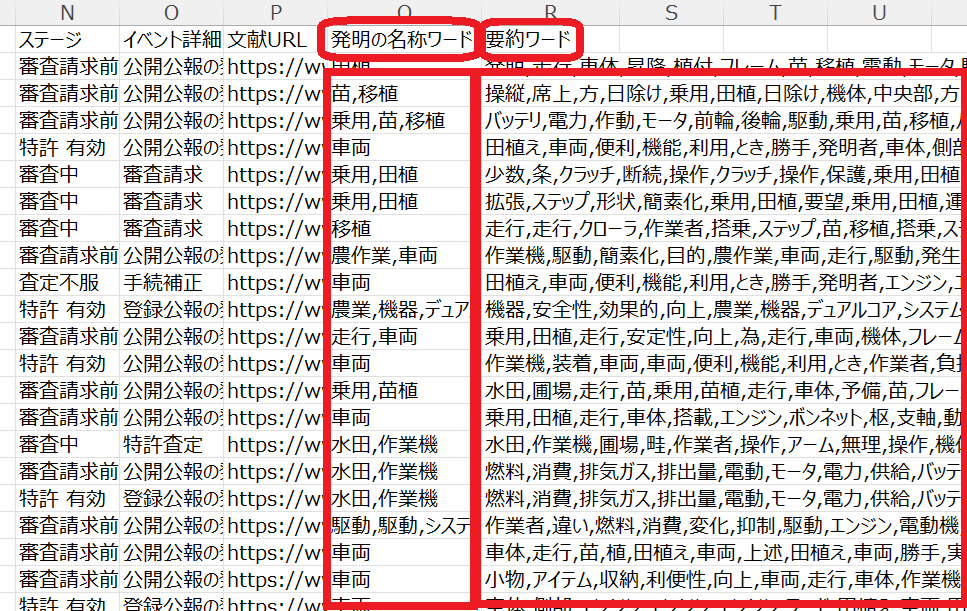
ふたつめは、テキストマイニングに切り出されたワードを、出現回数の多い順に並べた出現ワードリスト(CSVファイル)です。「出現ワードリストをダウンロード」をクリックすれば、ダウンロードされます。

ワードリストは、下図のように、発明の名称・要約の順に並んでいます。
3つめは、テキストマイニングで切り出されたワードを、出現頻度の多さに従ってビジュアルに配置された「ワードクラウド」です。
「発明の名称」と「要約」のそれぞれにひとつずつ作成されます。右クリックして別ウィンドウで表示したり、画像として保存も可能です。

なお、ご利用にあたっては、以下に留意いただきつつ、あくまで自己責任でお願い致します。
まだまだベータ版(完成手前で不具合を徐々に解消している段階)ですが、ご興味あるみなさま、いちど触ってみて、ご意見・ご感想などいただければ幸いです。
なお、ワンオペで開発しているので、ご希望をいただいてもタイムリーに応えられないかも知れませんが、温かく見守っていただければ😁
すでに試験運用を開始している特許マップ生成システム「Pat Map Generator」と共に、ご活用ください!
Views: 152






