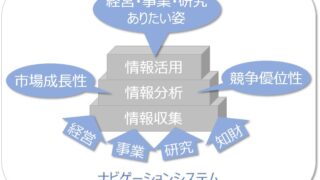
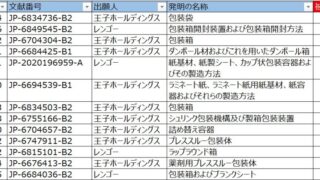
IPランドスケープで様々な情報解析を行うに当たり、テキストマイニングは欠かせない手段です。
昔は、特定の特許マップソフトを使うか、マニアックな専用ツールに手を出すか、くらいしか無かったのですが、機械学習に基づく手法が汎用になってきたこともあり、誰でも無料で手が出せるようになってきました。
無償ソフトウェアだと、KH Coderなどが有名どころですが、筆者は無償で利用できるWebサイトを幾つか使ってみています。
筆者は、ユーザーローカル社の「AIテキストマイニング」というサイトを使うことが多いです。利用可能な文字数も多く、解析速度も速くて、アウトプットの種類も割と豊富です。
以下、このユーザーローカル社のサイトを例に、今現在、テキストマイニングが無償でとこまでできるか、見てみたいと思います。
テキストの入力画面
ユーザーローカルのインターフェースは簡単で、コピペするだけ。結構な文字数でも一気に解析してくれます。数千件の特許でも、特に問題ないです。

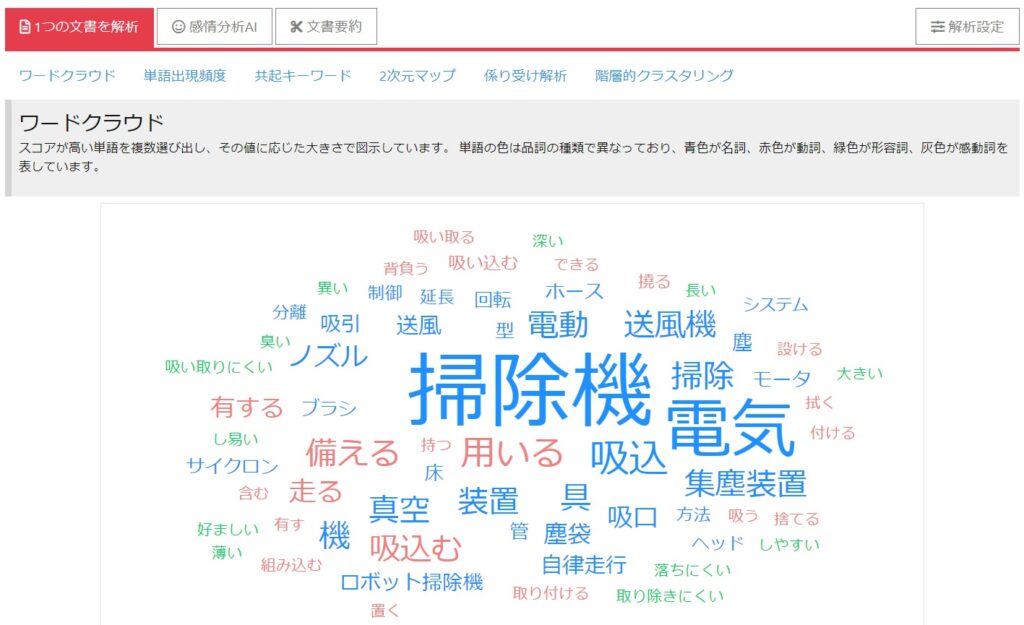
ワードクラウド
多いワードを大きく、そうでないものを小さく、近くに記述されるワード同士は近く、という感じで表示されます。これは、多くの有償特許検索ツールにも搭載され出しています。ユーザーローカルの場合、品詞で色分けもされます。
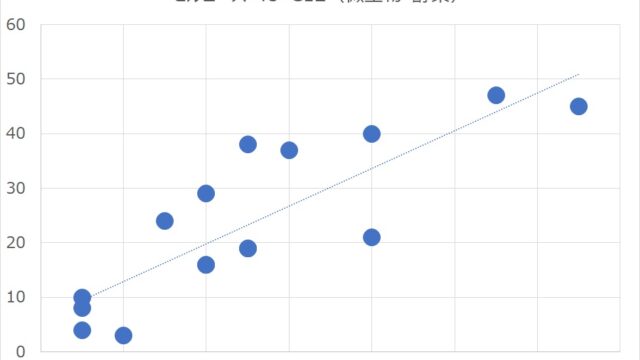
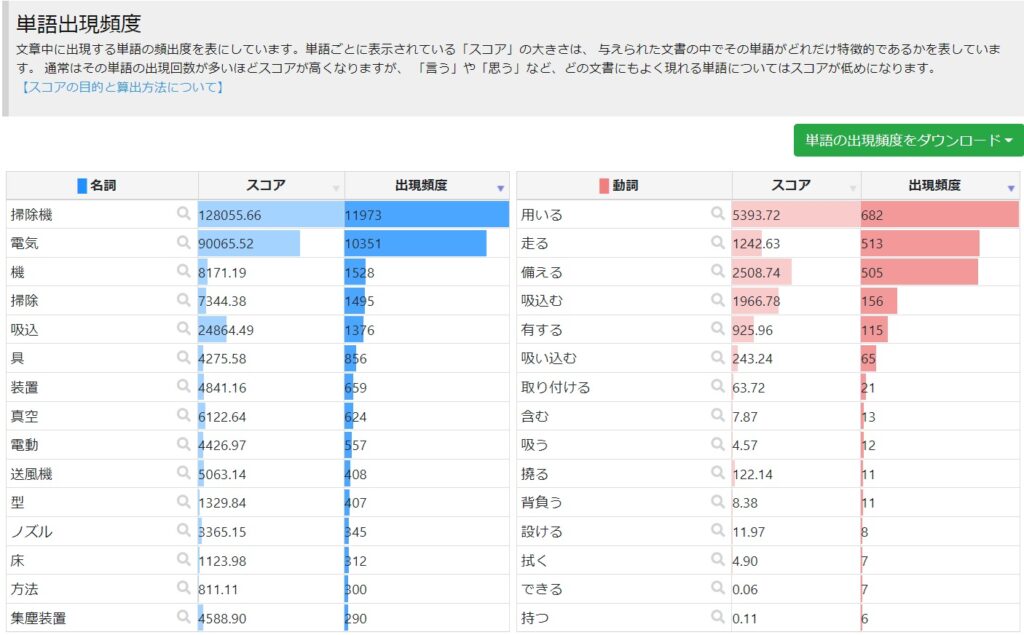
ワード出現頻度
筆者がよく使うのはこれです。出現頻度順に並んだワードを、ユーザーローカルではダウンロード可能。品詞別も表示されます。
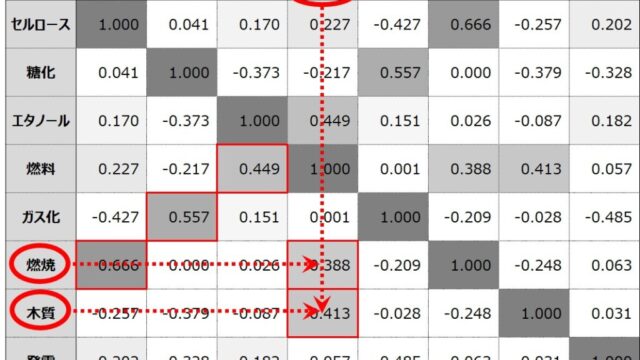
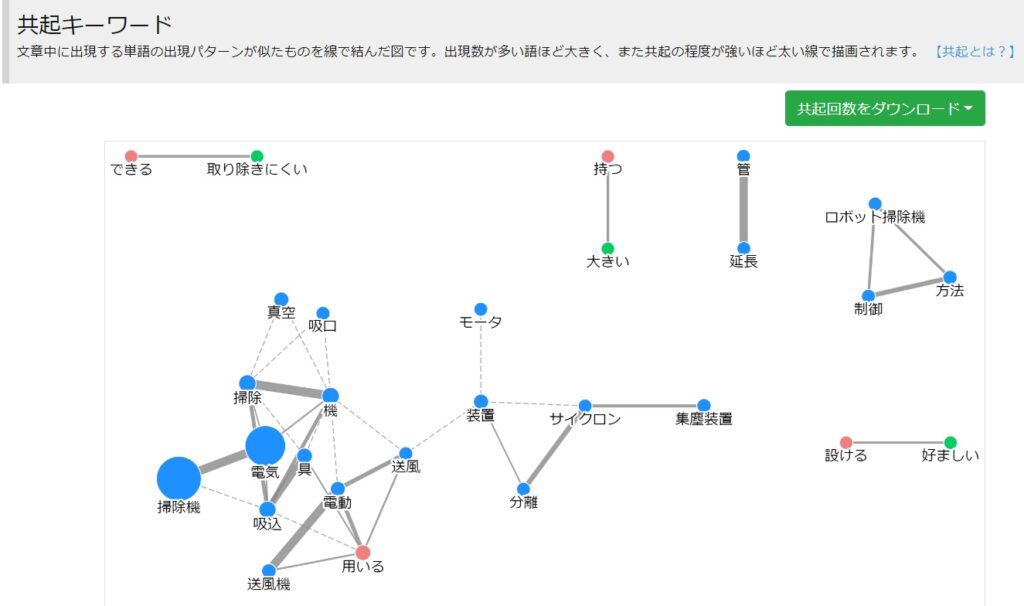
共起キーワード
一緒に出現することが多いキーワード同士が線で結んで表示されます。そのキーワードの意味合いを判別するのに便利です。
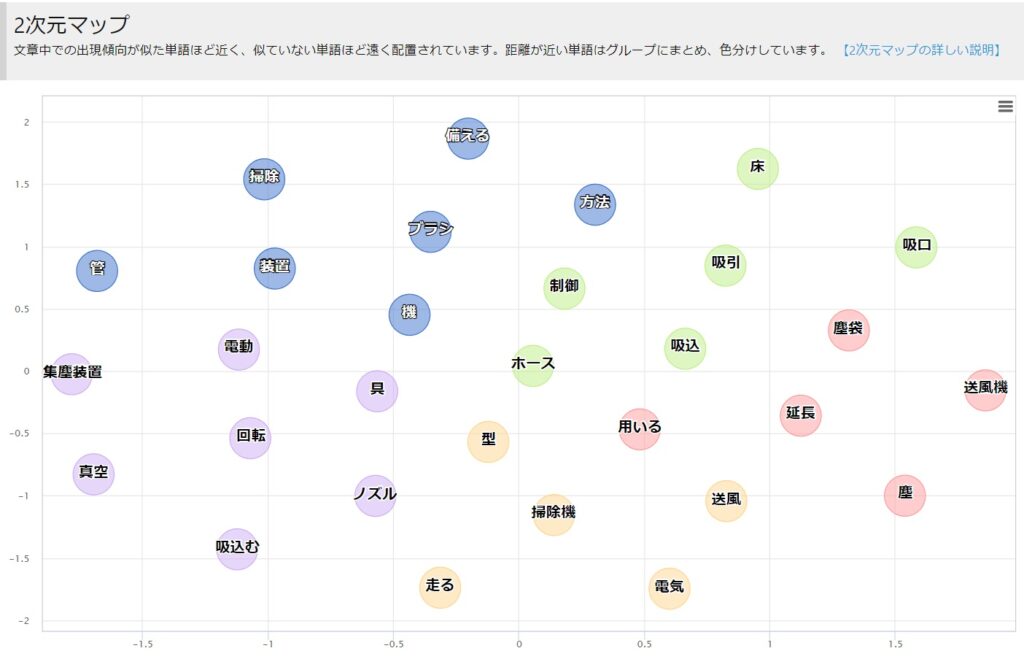
二次元マップ
出現する傾向が似たものが近く配置されます。筆者はあまり使いませんが、特許の塊が幾つあるかなど、判別する場合の傍証にはなるかと思われます。
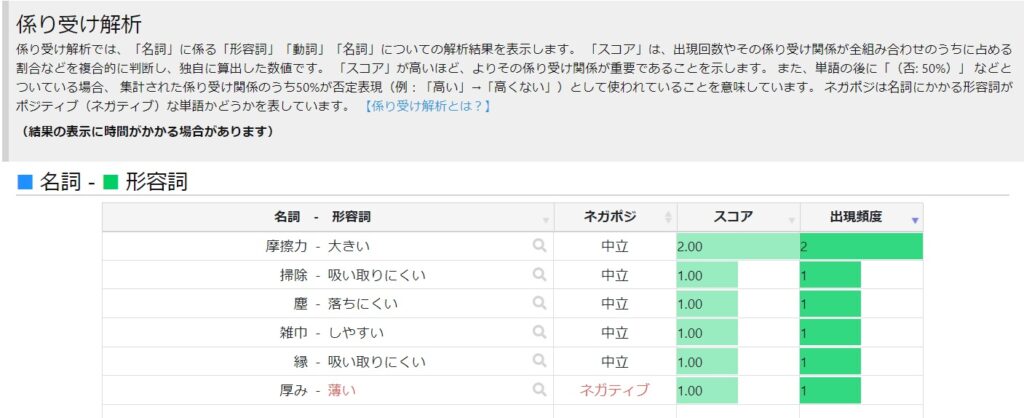
係り受け解析
そのワードがどんな意味合いで使われているか、係り受けの関係により分かり易くなります。
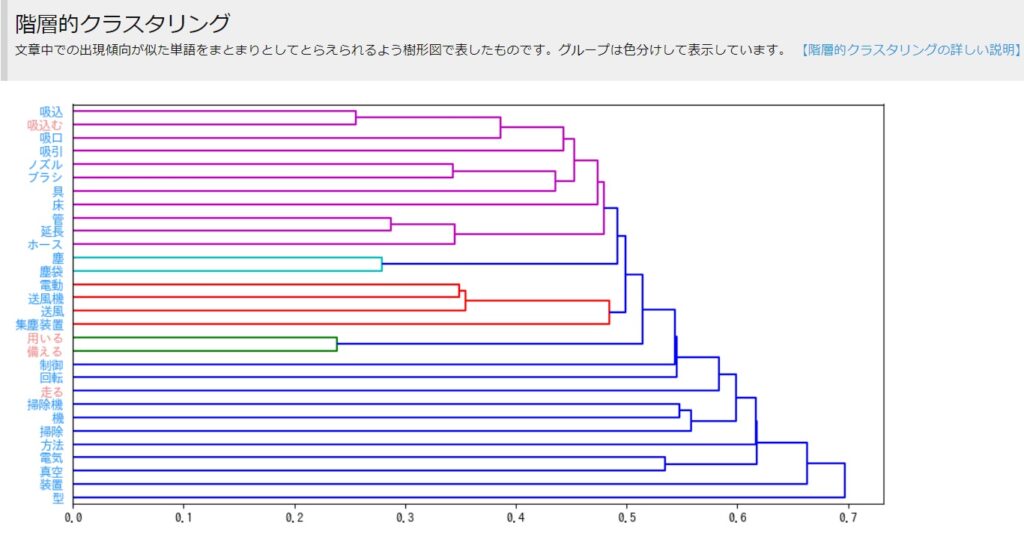
階層的クラスタリング
出願傾向が似たワードの関係性を樹形図で表示したものです。これも、特許の塊を捉える一助になります。
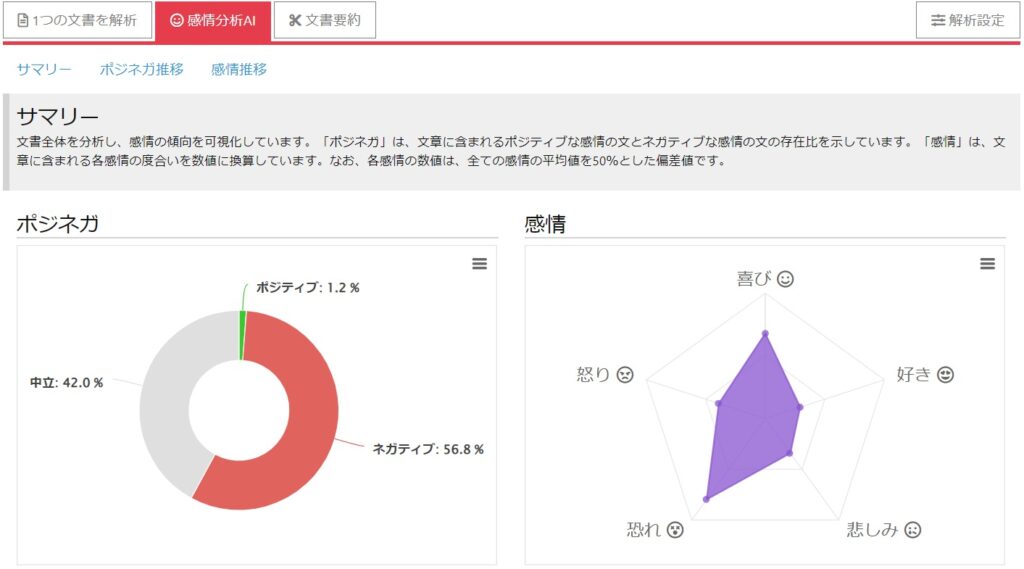
感情分析
その文章(群)が、喜怒哀楽など、どのような感情を表現しているか判別するという、おもしろい機能です。SNSのメッセージが非難か賞賛かなど、判別するのに使えるかと思われますが、特許分析ではあまり出番は無いかもですね。
お読みいただきまして、誠にありがとうございました!
ブログランキングに参加中!