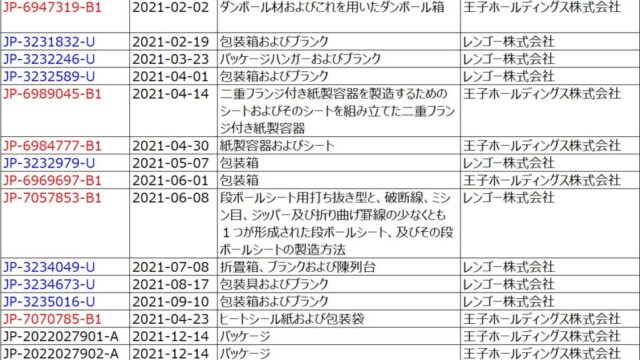
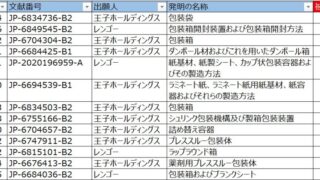
筆者はAI(人工知能)の専門家ではないですが、特許調査に関わる関係上、どうしても特許調査システムとAIとの関係を考える場面が多くなります。
特許調査システム内部のエンジンとしては、いわゆるAI、正確に言えば機械学習が普通に使われるようになってきました。深層学習(ディープラーニング)の本格活用となると、未だこれからという感じでしょうか。
一方、それが単なる検索ではなく、さらに、得られた検索結果の解析となると、まだまだという感があります。
※「どこからどこまでを解析っていうの?」と言われると、正直、答えるのは意外と難しいです。それは別の機会に触れたいと思います。
筆者がこれまで、いろいろなAIや調査システムのベンダーさん達と議論し、お願いし続けてきたのは、検索から解析までのプロセスをできるだけ省力化したい、ということでした。
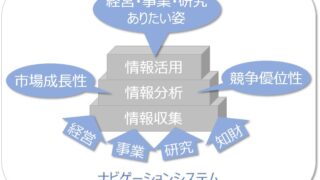
少なくとも、いわゆる特許マップソフトを使ってできるようなビジュアル化は、AIも活用して完全自動化できるのではと。それを「即時ミエル化」と称して、IPランドスケープを推進する環境を整えるための必要条件として掲げていました。
2017年頃から言い始めて、それは今もって実現できていませんが、今現在、AIの進化と絡めて、思うところを述べてみたいと思います。
先行文献調査 vs 技術動向調査
よくある特許調査としては、先行文献調査と技術動向調査が挙げられるかと思います。両者は混同されることも多いですが、簡単に言ってしまうと以下の違いがあるかと思います。
- 先行文献調査:対象となる研究開発や事業のテーマが明確で、それに対して先行する同様の研究開発や事業に関して記述した文献をピックアップすること
- 技術動向調査:対象となる研究開発や事業のテーマは未定だが、技術や事業のタネみたいなものが頭の中にあるという段階で、関連する研究開発や事業がどのように動いているか、様々な切り口から把握すること
別の言い方をすると、以下のようにも言えるかと思います。
- 先行文献調査:答えや目標がある(類似とされる先行文献を列挙すればゴール)
- 技術動向調査:答えや目標がない(どうすればゴールなのか当初には分からない)
ここで、「技術動向調査に目標がない、なんてありえない!」と言われそうですが、たとえば、「いったん特許増減のトレンドを見てみる」というのは、ここでは目標ではない、とします。
そのトレンドに基づいて、たとえば「だから市場が伸びていると言える」「だから競争優位と言える」というところまで言及することを目標としています。
そういう意味では、「答えがある・ない」というより、「答えがわかる・わからない」という方が正解かも知れません。
教師あり学習 vs 教師なし学習
上述した「答えがある・わかる」「答えがない・わからない」ということは、機械学習で使われる「教師あり学習」「教師なし学習」と共通するところがあります。
「教師あり学習」と「教師なし学習」の違いは、かなり大雑把ですが、以下のようになります。
- 教師あり学習:答えを与えながら、大量の情報の当否を、認識・判断させること
- 教師なし学習:答えを与えず、大量の情報から、共通の特徴を把握・分類させること
つまり、「教師あり学習」は、答えがある・わかっている状態を前提に、認識・判断の正解率を上げていくプロセスと言えます。先行文献調査は、見る人が見れば、「先行文献である」「先行文献でない」が判別できると思われますから、こちらに近いと思われます。
一方、「教師なし学習」は、答えがない・わかっていない状態を前提に、とにかく共通の特徴を見極めて、特徴別に分類するプロセスと言えます。ヒートマップなどはこの典型例と言え、いわゆる技術動向調査は、おおむねこの性質があると思われます。
「即時ミエル化」への期待
現在、特許調査システムには、いわゆる特許分析をビジュアル表現する機能が標準で備わるようになってきています。(有料オプションの場合も多いですが)
クラスタリングや類似度ランキングなどは、機械学習の成果で、一部にはディープラーニングの簡単なものが応用されているかと推察します。いわゆる「ダッシュボード」として、簡単なものなら表示できるようになってきています。
しかし、いわゆるBIツールと比べると、広範なデータを、リアルタイム性高く、柔軟な表現方法で示すには、まだまだだなあ、という感じです。また、BIツールを使っても(使いこなせてはいませんが・・・)、「カユいところに手が届く」レベルには遠いと感じます。
「即時ミエル化」で期待するのは、BIツールで実現できるレベルを踏まえた上で、さらに先、「経営・事業・研究の方針の成否を判断し、目標を指し示す」ために有用なビジュアルのパターンを即時に示すことです。
しかも、「なにが有用なのか?」は、会社によって大きく違うでしょうから、その会社なりに有用と思われるパターンを、判別したり分類したりするには、「機械学習」によるのが好都合と、筆者は考えています。
そのような機械学習ができるような環境を社内に構築したい、というのが筆者の願いですが、もし、すでに実現されているところがあれば、ご教示いただければ幸いです。こちらから出せる情報は乏しいかも知れませんが、意見交換だけでもさせていただけると嬉しいです。
お読みいただきまして、誠にありがとうございました!
ブログランキングに参加中!